
One of the challenges of setting up an MFT Server active-active high availability cluster is in preventing duplicate trigger executions, especially for triggers that use the Current Time event or Directory Monitor-based events. Most of the time, you only want one node in the cluster to execute a particular trigger.
Prefer to watch a video version of this tutorial instead? Play the video below. Otherwise, skip it and proceed to the rest of the article below.
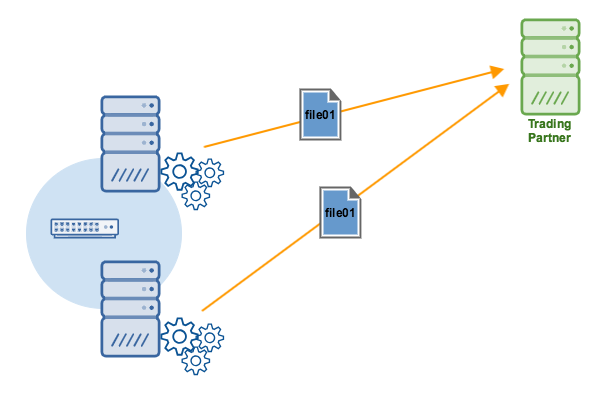
So, let’s say you’ve built an active-active SFTP HA cluster consisting of two instances of JSCAPE MFT Server. And you’ve pointed those two instances to a common RDBMS, so any changes made to the settings of one MFT Server instance would be automatically reflected to the other instance. Pretty cool.
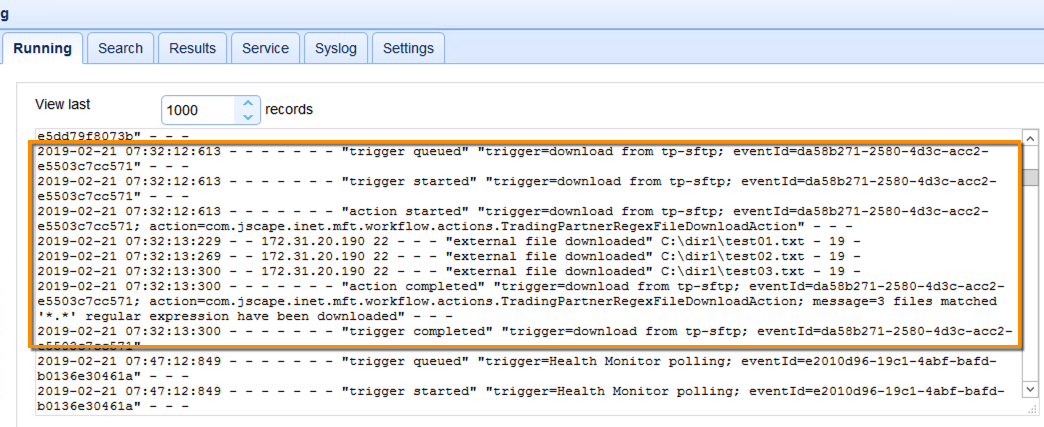
And so, you sit back, relax, and just watch files get moved around between your server and various trading partners or end users. And you start feeling pretty good about what you’ve accomplished so far — until, you glance at your logs and you start seeing what look like duplicate trigger executions. Basically, you look at the running log of your first instance and you see something like this:
Running domain logs on MFT Server 1
The race condition problem

At first glance, that might seem pretty harmless. Just a trigger connecting to an SFTP trading partner and downloading 3 files. Nothing extraordinary there. However, when you check the running logs of your second MFT Server instance, you see a very similar set of log entries.
Did you know that you could test this out in your own environment?
Get a free trial of JSCAPE when you request it here.
Running domain logs on MFT Server 2
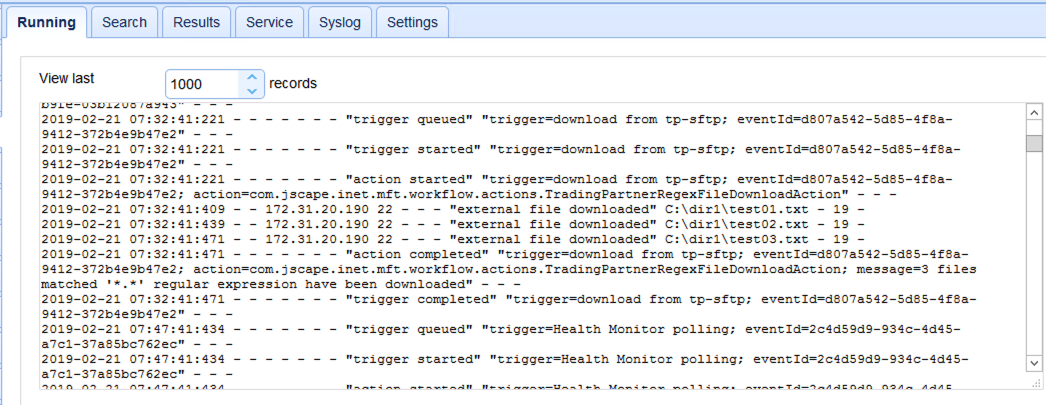
Actually, aside from very minimal differences in the timestamps, this trigger execution on the second instance is really exactly the same trigger that’s executing on the 1st instance. You don’t want that to happen. What you’re seeing here is a race condition consisting of the same trigger (but on different MFT Server instances) running at the same time.
These race conditions could lead to undesirable consequences, like missing files, incomplete transfers, duplicate transmissions (which can really upset your trading partner), and several other issues. This problem usually happens when you have a trigger that uses the Current Time event type or when you have a trigger that depends on a Directory Monitor-type of event, especially when the directory being monitored is shared between the two MFT Server instances, which is pretty normal when you have an HA cluster.
Race conditions caused by time-based triggers
The problem with having time-based triggers in active-active HA configurations of MFT Server is that, once the scheduled time arrives, both triggers will execute. So, let’s say you have a trigger on MFT Server 1 that’s scheduled to send out a file to a trading partner named TP1 at 7:32 AM everyday. The moment the clock strikes 7:32 AM, MFT Server 1 will transmit the file in question to TP1. That shouldn’t be a problem, right?
But, by virtue of being a node in an active-active HA cluster, MFT Server 2 would also have that same trigger. Thus, MFT Server 2 will also transmit the same file to the same trading partner at approximately the same time. Just like what you saw in the logs. These duplicate trigger executions can cause a lot of confusion.
Race conditions caused by directory monitors
A similar thing happens when you have a trigger that responds to certain directory monitor events. Let me explain. When you have an active-active HA configuration, each node will usually be monitoring the same directory in a shared storage system.
So, if a monitored event occurs in that directory (e.g. a file is added, a file is deleted, a file is modified, or a file’s age exceeds a certain number of days) that event will be detected by each node in the cluster. As a result, any trigger listening to that event will execute. And again, because this is an HA configuration, the same trigger will execute on all nodes in the cluster.
Getting rid of race conditions with the Health Monitor trigger action
One way to solve this kind of problem is by using the Health Monitor trigger action. This trigger action has two main parameters: the name of a Global Variable and the path of a certain hosts file.

As with all global variables, this particular global variable can be found in Triggers > Settings.
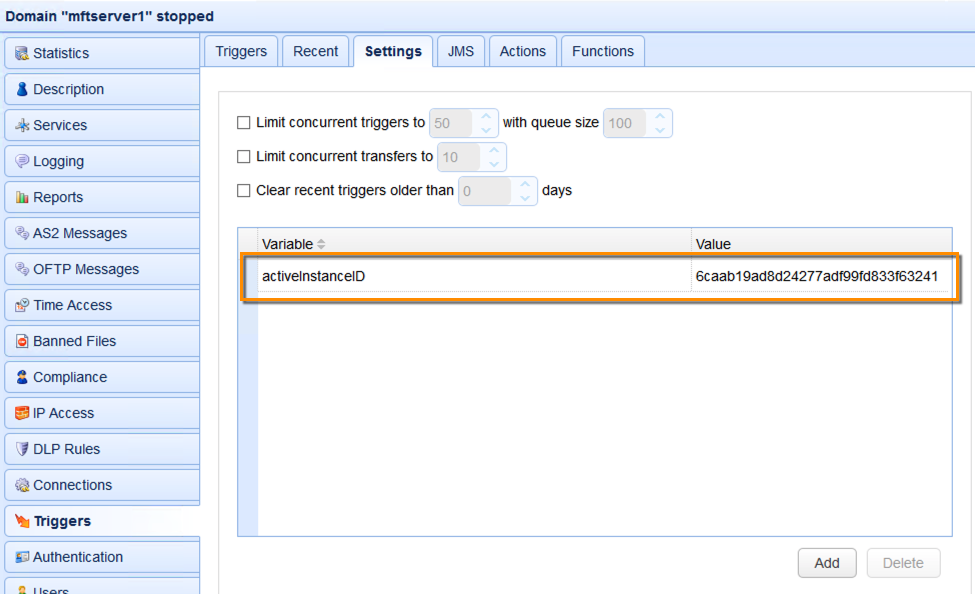
The name of the global variable we used for this tutorial is ‘activeInstanceID’. This name is arbitrary. You can call it whatever you want. Right now, the value of our activeInstanceID global variable is 6caab19ad8d24277adf99fd833f63241. We’ll explain how our global variable got that value in a short while. For now, let’s go back to that Health Monitor trigger action.
This trigger action runs through a list of hosts listed in a specially formatted hosts file, whose location is specified in this trigger’s Hosts File parameter. Starting from the top of the list, the trigger polls these hosts to check if they are up and running. As soon as it discovers an active host, it then assigns the value corresponding to that particular host in the host file to that global variable we showed you earlier.
Here’s how the contents of that host file would look like:
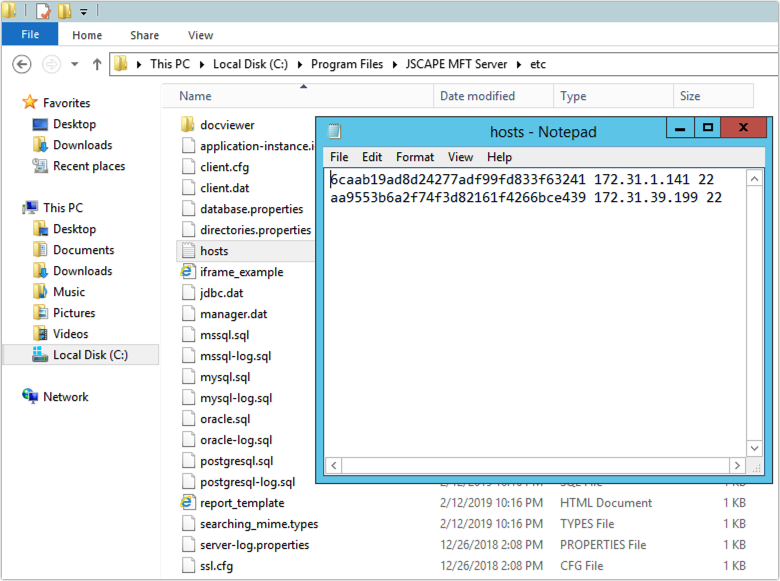
I named the file hosts.txt and placed it inside the [etc] folder under the MFT Server installation directory but you can give it any name you want and place it anywhere on your server. Just be sure:
1. The hosts file filename AND its contents are the same across all MFT Server nodes and
2. The hosts file is placed in exactly the same folder on all MFT Server nodes.
So, in my case, all my MFT Server nodes each have a hosts file named hosts.txt and that file is always placed in the [etc] directory of each node’s MFT Server installation directory.
Breaking down the contents of the hosts file
Let’s now break down the contents of that hosts file. Each line in the file will always consist of the following elements:
[global variable value] [space] [host/IP] [space] [port number] [new line(\r or \n or \r\n]
So, if we review the screenshot above and exclude the spaces and new lines, we have:
| Global variable value | Hostname or IP address | Port number |
| 6caab19ad8d24277adf99fd833f63241 | 172.31.1.141 | 22 |
| aa9553b6a2f74f3d82161f4266bce439 | 172.31.39.199 | 22 |
172.31.1.141 and 172.31.39.199 are just the IP addresses of the nodes that compose my HA cluster and 22 are the port numbers of services I’m expecting each of these nodes to be listening on.
When the Health Monitor trigger action runs, it will first poll the host in the topmost entry (which, in our case, is 172.31.1.141). If that host (and the specified service) is available, then the trigger will assign that host’s corresponding value (in our case, 6caab…) to the activeInstanceID global variable we showed you earlier.
If that first host is unavailable, the trigger will then proceed to the next one and poll it. If that one is available, the trigger will then assign that host’s corresponding value (in our case, aa955…) to the global variable.
If none of the hosts are available, you’ll see something like “Unable to connect to any hosts” in the domain logs.
Normally, you would want the polling to be done periodically. So, the best way to do that is to run this trigger action from a time-based trigger. You can just create a trigger that uses the Current Time event type and leave the trigger conditions box empty. This will execute the Health Monitor trigger action every minute.
So, now, all you’ve got to do is modify your other Current Time triggers, those triggers that respond to Directory Monitor events, and all other triggers that are susceptible to duplicate executions, and add a condition that will restrict execution of those triggers to a single active instance. So, for example, I have a trigger that’s supposed to send out files every 8:10 AM. I will then add the following condition to that trigger’s condition box:
ApplicationInstanceId = GetGlobalVariable("activeInstanceID")
So, the complete expression will look like this:

This expression will obtain the current value of the activeInstanceID global variable and compare that with this MFT Server instance’s ApplicationInstanceID.
If the two values match, then this MFT Server instance will execute this trigger. If the two values are not equal, that means this MFT Server instance SHOULD NOT execute this trigger.
That’s it. Now you know how to prevent duplicate trigger executions in an MFT Server HA Cluster by using the Health Monitor trigger action.
Would you like to try this out yourself?
Request a free trial to get started testing features in your own environment.

