

Overview
Hashes are essential to secure file transfers. You can find them in operations involving passwords, file integrity checks, digital signatures, digital certificate thumbprints or fingerprints, and others. But what are hashes? In this post, we'll introduce you to hashes, the concept of hashing, and its applications in various areas of security.

What is hashing?
Hashing is an operation that takes any string of text, regardless of length or size, as input and then provides a fixed-length string of characters as output.
Here are some sample text and their equivalent hashes:
| Text | Equivalent hash |
| the quick brown fox jumps over the lazy dog | 77add1d5f41223d5582fca736a5cb335 |
| the quick | e8394495128fcd958836523af1601f00 |
| the quikk | d58f6b5a222de711eb8cc4580b8459b0 |
There are two things that immediately stand out here:
1. The lengths of the equivalent hashes in the examples are exactly the same (in this case 32 characters long), regardless of the lengths of their original text. This is what I meant by hashes having a fixed-length. This behavior should hold true even if the original text is a single word or a 1,000-page document.
and
2. Even a slight difference in the original text ("the quick" vs "the quikk") results in two different hashes.
We'll dive into the implications of these two characteristics shortly.
Encryption vs Hashing
A hash looks pretty much like the output of an encryption operation (a.k.a. ciphertext) does it? Well, encryption and hashing operations do have similarities. However, they also have a couple of differences. First of all, unlike encryption, hashing is always one way. In fact, hashing is often called "one way encryption". So, while you can decrypt an encrypted text, you cannot "de-hash" a hashed text. We'll see why this can be a useful feature when we explain how hashes are used, e.g. in password authentication systems.
Properties of secure cryptographic hash functions
When hash functions (the underlying functions responsible for mapping the original text into a hash) are used in information security, they must adhere to certain properties. These three are the most important:
1. They must be efficient. The cryptographic hash function must not consume a lot of CPU cycles even if it's made to operate on a huge file.
2. They must be one way functions. Meaning, it should be virtually impossible to obtain the original text (a.k.a. the pre-image of the hash) from the hash.
3. They must have collision resistance. This means that it should be virtually impossible to find two different text or documents that would yield the same hash.
These are just idealised properties. In the real world, especially with the constant emergence of more powerful computers, it may be impossible to arrive at a hash function that would totally and forever uphold these three properties. Indeed, there are hashing algorithms that are no longer considered secure. Still, strong hashing algorithms can last long enough to be used extensively in securing business transactions until a technology or technique capable of breaking them comes along.
Let's take a look at some of the more commonly used hash algorithms.
Commonly used hash algorithms
Some of the commonly used hashing algorithms include:
MD5
Message Digest 5 or MD5 was developed by Ron Rivest, whose name is immortalised as the R in RSA (a public key cryptosystem common in various secure FTP protocols ). MD5 uses multiples of 512 bits as input and produces a 128-bit message digest (or the hash) as output. It is one of the older hashing algorithms but is now known to have certain vulnerabilities in its collision resistance properties.
SHA1
Like the MD5 hash, SHA1 (secure hash algorithm) also takes 512 bits of input at a time. However, its output is 160 bits. SHA-1 was the result of a joint project between the NSA and the NIST. Like MD5, this cryptographic hash function has been proven to be relatively vulnerable to certain collision attacks.
CRC
CRC or Cyclic Redundancy Check is an example of a non-cryptographic hash function. Compared to cryptographic hash functions, CRC hash functions can be easily reversed. Hence, it isn't ideal for applications (e.g. digital signatures) that require functions with strong irreversibility properties. It's more suitable for detecting accidental changes in stored or transmitted files. In other words, it's used for data integrity checks.
SHA-2
Once the SHA1 hash function was found to have potential vulnerabilities, the NSA decided to design a set of stronger hash functions. The resulting product was SHA-2, a family of hash functions that had 224, 256 and 384, and 512 bits. These were known respectively as SHA224, SHA256, SHA384, and SHA512.
We now look at some of the applications of hashing.
Hashing passwords
Secure systems never store passwords in the clear. That is, if you look at a password file, the list of usernames and their corresponding passwords wouldn't look like this:
peter: password1234
james: mac@pRoS
sharon: shadowfax
Instead, it would likely look like this:
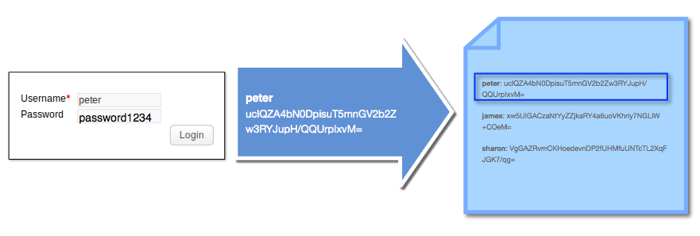
peter: uclQZA4bN0DpisuT5mnGV2b2Zw3RYJupH/QQUrpIxvM=
james: xw5UIGACzaNtYyZZjkaRY4a6uoVKhriy7NGLlW+COeM=
sharon: VgGAZRvmCKHoedevnDP2fUHMfuUNTcTL2XqFJGK7/qg=
The strings of characters you see after the equal signs are actually hashes (actually, base-64 equivalents of hashes if you want to be more accurate) of each password. When a user logs in, the system first grabs whatever is entered into the password field and converts that into a password hash. It's that hash that's used when looking up the username/password pair in the password file. If a match is found, the user is allowed entry.
That way, even if an attacker gets a hold of the password hash file, he wouldn't be able to use that file to login to the system.
Hashing is better than encryption in this case because it eliminates the possibility of the hashed password being converted back to its plaintext equivalent. If you use encryption, it would be possible for an attacker to acquire all passwords (in plaintext) if he were somehow able to acquire the decryption key.
Integrity checking
Remember the second characteristic we were able to observe in the section "What is hashing?"? If you recall, we noticed that even the slightest change in the original text can result in an entirely different hash. This characteristic can be put to good use in data integrity checks. Let me give you a simple example.
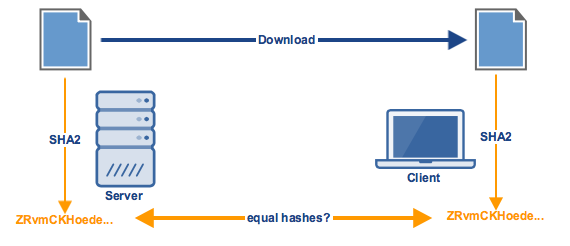
Let's say a user wants to download an important electronic document from a server. Because the integrity of the data in that document is important to him, he would like to know if the document is altered along the way. One way to do achieve this is by using a client and a server that supports the same hash function.
Before sending the file, the server must first obtain a hash value of the file using that hash function. Once the client receives the file, it too must use the same hash function to generate a hash value. The two hash values must then be compared. If the two values are equal, then it would be safe to conclude that the file has been unchanged.
Digital signatures
Most data integrity checks are only carried out by the client. When a file is downloaded, it's usually already accompanied by the file's hash a.k.a. message digest. The client then generates its own hash from the file it downloaded and compares it with the message digest that came along with the download. This method has a flaw.
What's to stop an attacker from intercepting the file, altering it, generating its own message digest using the same hash function, and then forwarding the altered file (along with the new message digest) to the client? Once the client receives the downloaded file and compares its locally-generated hash with the downloaded hash, they will naturally appear equal. No way will this qualify for a HIPAA compliant file transfer. It's therefore important for the client to make sure that both the downloaded file and the downloaded hash came from the original source.
This can be done using asymmetric encryption keys. Assuming the client has the corresponding public key, the server can generate a "digital signature" using its private key and the message digest. Its this digital signature that will then be sent together with the file. So, when the client receives them, it can then use the public key to verify the authenticity of the signature and retrieve the message digest. Only then can the client compare the message digest with its locally-generated hash of the file.
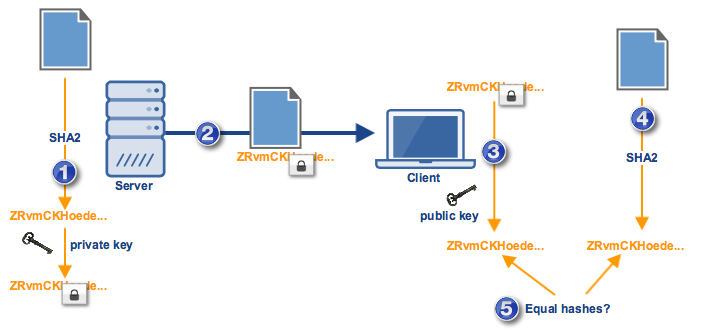
A failure to authenticate could only mean that the private key that was used to generate the digital signature is not the pair of the public key used by the client. Digital signatures are common in SSL-secured protocols like FTPS.
There are several other applications of hashing. Hopefully, we can discuss those in another post. But let's end here for now.
If you like to read more posts like this, subscribe to this blog or connect with us.
Get started
Download a free, fully-functional edition of JSCAPE MFT Server today.