

Small and medium-sized businesses in the US typically have Internet connections with upload speeds of up to 10 Mbps (Megabits per second). At that speed, a 100 GB upload will need about a day to complete. Most people, on the other hand, have upload speeds of only around 0.6 Mbps. This would theoretically translate to a 2-day upload for the same 100 GB load.
But how about those companies that handle terabytes of data? Here are upload times of a one (1) terabyte load over some of the more common Internet network technologies (This is from a blog posted by Werner Vogels, Amazon.com's CTO):
| DSL | 166 Days |
| T1 | 82 Days |
| 10 Mbps | 13 Days |
| T3 | 3 Days |
| 100 Mbps | 1-2 days |
| 1 Gbps | less than a day |
For companies who deal with hundreds of terabytes like those serving online movies, uploading files at these speeds is simply not feasible. Clearly, when you put together the size of big data and the width of the pipe (i.e., your Internet connection) you're going to transport it through, what you'll get is an insanely slow process.
That is why even Amazon is offering a "manual" transport service for those customers who are looking for a faster solution for moving volumes of data to the cloud. This service, known as AWS Import/Export, involves shipping portable storage devices whose data contents are then loaded up to Amazon S3.
Increasing bandwidth certainly looks like a logical solution. Unfortunately, file sizes and bandwidths aren't the only things that factor into a big data transfer.
All those upload speeds are actually only good in theory. In the real world, you really can't just get an estimate of the upload time based on your bandwidth and your file size. That's because you need to factor in a couple more things that can slow the process even more. One of it is your location with respect to that specific part of the cloud you'll be uploading files to. The farther the distance, the longer uploads will take.
Where our problem lies
The root of the problem lies in the very nature of the network technology (or protocol) we normally use to transfer files, which is TCP (Transmission Control Protocol). TCP is very senstitive to network conditions like latency and packet loss. Sadly, when you have to transfer big files over a Wide Area Network (WAN), which really sits between your offline data and your destination in the cloud, latency and packet loss can adversely affect your transfer in a big way.
I won't be discussing the technical details of this problem here but if you want to know more about it, how serious it is, and how we are able to solve it, I encourage you to download the whitepaper entitled "How to Boost File Transfer Speeds 100x Without Increasing Your Bandwidth".
For now, let me just say that even if you increase your bandwidth, latency and packet loss can bring down your effective througphut (actual transfer speed) substantially. Again, depending where you are with respect to your destination in the cloud, your effective throughput can be only 50% to even just 1% of what is being advertised. Not very cost-effective, is it?
The fastest way to send large files to the cloud
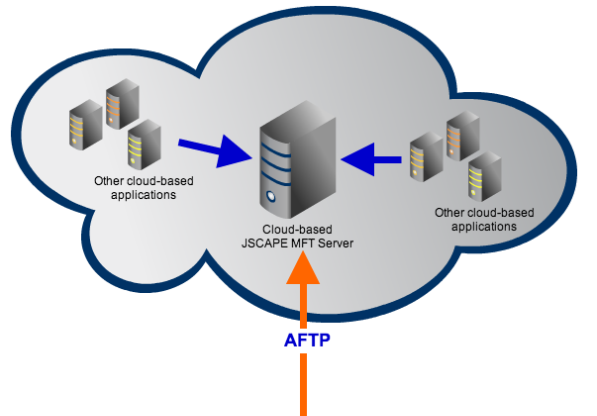
A better way to transfer big files to the cloud would be to take advantage of a hybrid transfer protocol known as AFTP (Accelerated File Transfer Protocol). This protocol is a TCP/UDP hybrid that can boost file transfer speeds up to 100%, which practically cancels out the effects of latency and packet loss.
Because AFTP is supported by JSCAPE MFT Server, you can deploy an EC2 instance of JSCAPE MFT Server on Amazon and then use it to provide an AFTP file transfer service. For zero financial risk, you can give the free evaluation version a test run be clicking the download button at the end of this blog post. Once your server is set up, you can then upload files via an AFTP-enabled file transfer client like AnyClient (it's also free) or a locally installed instance of JSCAPE MFT Server.
As soon as you've moved all your data to the cloud, you can make them available to other cloud-based applications.
Summary
Poor network conditions can prevent you from harnessing the potential of big data cloud computing. One way to address this problem is by avoiding an Internet file transfer altogether and simply shipping portable storage devices containing your data to your cloud service providers.
Or you can use AFTP.
Recommended Downloads
Download JSCAPE MFT Server Trial